OpenRooms: An Open Framework
for Photorealistic Indoor Scene Datasets
CVPR 2021 (Oral presentation)
- Zhengqin Li 1
- Ting-Wei Yu1
- Shen Sang1
- Sarah Wang1
- Meng Song 1
- Yuhan Liu1
- Yu-Ying Yeh 1
- Rui Zhu 1
- Nitesh Gundavarapu 1
- Jia Shi1
- Sai Bi 1
- Zexiang Xu 1
- Hong-Xing Yu 1
- Kalyan Sunkavalli 2
- Miloš Hašan 2
- Ravi Ramamoorthi 1
- Manmohan Chandraker 1
- 1UC San Diego
- 2Adobe



Overview
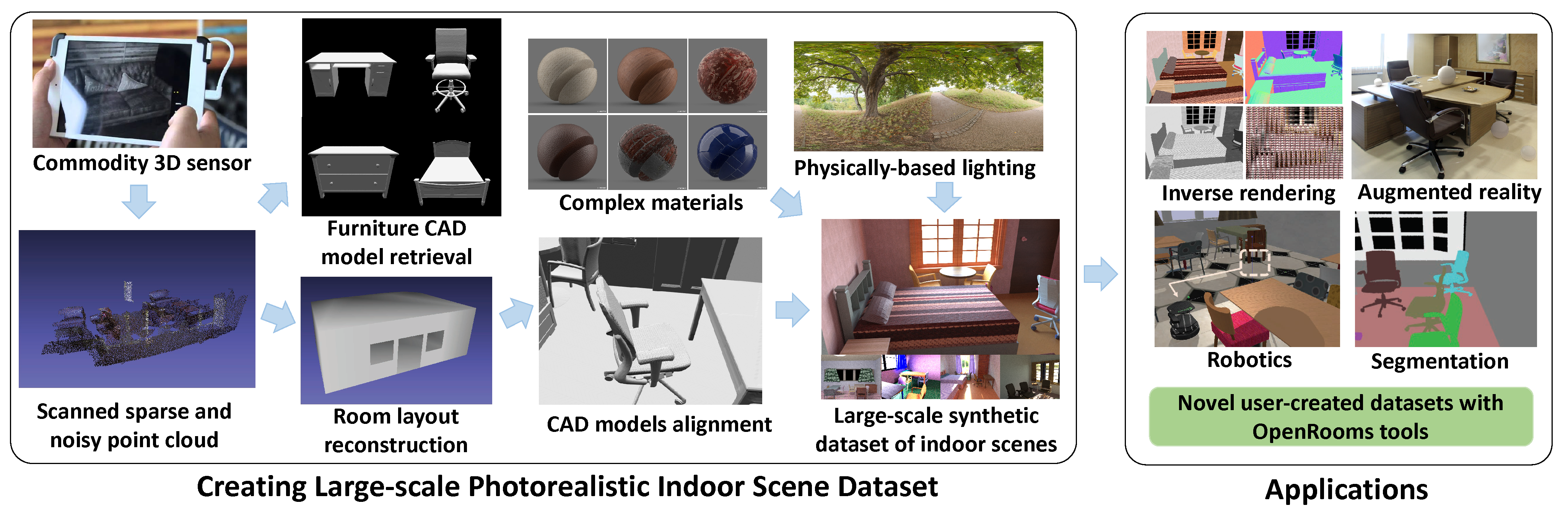
Large-scale photorealistic datasets of indoor scenes, with ground truth geometry, materials and lighting, are important for deep learning applications in scene reconstruction and augmented reality. The associated shape, material and lighting assets can be scanned or artist-created, both of which are expensive; the resulting data is usually proprietary. We aim to make the dataset creation process for indoor scenes widely accessible, allowing researchers to transform casually acquired scans to large-scale datasets with high-quality ground truth. We achieve this by estimating consistent furniture and scene layout, ascribing high quality materials to all surfaces and rendering images with spatially-varying lighting consisting of area lights and environment maps. We demonstrate an instantiation of our approach on the publicly available ScanNet dataset. Deep networks trained on our proposed dataset achieve competitive performance for shape, material and lighting estimation on real images and can be used for photorealistic augmented reality applications, such as object insertion and material editing. Importantly, the dataset and all the tools to create such datasets from scans will be released, enabling others in the community to easily build large-scale datasets of their own.
Highlights
- A dataset with high-quality ground truth SVBRDF and spatially-varying lighting.
- Photorealistic rendering with a GPU-accelerated physically-based renderer.
- Goal of open dataset with no proprietary assets, along with tools for users to create their own datasets.
- State-of-the-art performance when used as training data for inverse rendering tasks.
- All code, trained models, rendered images and other ground truth to be publicly available.
Technical Video
Download
To download the dataset, please send your request to the email OpenRoomsDataset@gmail.com. A download link will be sent to you once the dataset is released.